(顶刊)一个基于分类代理模型的超多目标优化算法
《A Classification Based Surrogate-Assisted Evolutionary Algorithm for Expensive Many-Objective Optimization》
摘要
提出了一种基于分类模型网络预测的模型,比较candidate solutions 和 reference solutions之间的支配关系而不是去分别对目标值进行近似,考虑预测时的不确定性和分类的类别进行个体选择。
创新点
1、是做分类,但是是和分类边界(参考解)进行比较,而不是每个个体之间进行相互比较
2、选择的参考解可以很好地保持种群的收敛性和多样性,没有使用主流的三类MOEA方法,而是使用了基于径向过程的方式来进行环境选择
3、考虑到模型可能发生错误,使用了交叉验证和可信度配置的方式验证模型的效果
速看版本

- 使用径向过程将m维目标空间投影到2维,在2维径向空间里使用网格的方式选点作为分类参考点,本文经过实验对比选定k=6
- 使用真实的目标函数依次与参考点集合进行支配关系对比,将种群分为Ⅰ(被支配的)和Ⅱ(非支配的)两类
- 分别在Ⅰ、Ⅱ中按照1:3选择验证集和测试集,使用训练集进行网络的训练,网络使用了基础的FNN
- 使用验证集对网络进行验证,并根据原始的分类与预测的结果得到可信度支配结果
- 使用模型进行个体选择
- 再次使用径向方式投影,并用网格的方法进行环境选择
- 循环上述所有步骤,直到 F E > F E m a x FE > FE_{max} FE>FEmax
实现框架
模型:a classification based surrogate-assisted evolutionary algorithm(CSEA)
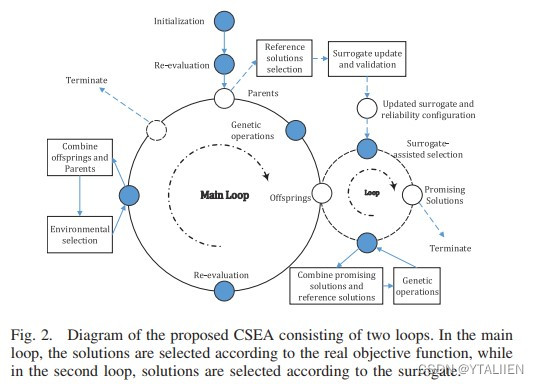
1、初始化
使用LHS采样生成初始种群P,使用随机生成的权重参数构成的三层的FNN,隐层有H个神经元,激活函数是sigmoid。并使用objective function来预测解,得到解对应的目标值,并将这些目标值和对应的解存档。
2、选择参考解构建分类模型
使用基于径向的选择方法从1中的存档中选择解生成参考解种群
P
R
P_R
PR,作为分类的边界
3、模型更新和验证
根据分类的边界,使用分类模型将步骤1中存档的解分为两类,在径向空间里可以表现为被参考解支配或是支配参考解,并将这些解根据3:1的比例作为训练数据和测试数据,使用交叉验证方法来评估模型的可靠性,构建训练分类模型
4、模型辅助的选择(surrogate-assisted selection)
在1生成的种群P中使用交叉和变异来生成下一代,根据分类模型的结果和模型可信度(所预测的解的确定度)从子代中选出有希望的解(promising solutions),加入存档Arc中,作为下一迭代的训练数据
5、环境选择
使用径向过程选择从中间种群中选出N个作为下一代种群
6、结束
循环2,3,4,5,直到
F
E
>
F
E
m
a
x
FE>FE_{max}
FE>FEmax,该算法停止
细节详细说明
A)分类边界定义
根据产生的参考解生成一个分类边界,根据在径向空间中与分类边界对应的支配关系被分为Ⅰ/Ⅱ类(即:Ⅱ类支配参考解,参考解支配Ⅰ类)
将m维的目标向量投影到2维的径向空间,2维的径向空间(radial space)被分成一个一个的网格


W:投影矩阵
K:所需要选择解的个数=参考解的个数=种群大小
C
o
n
Con
Con:在目标空间里计算理想点和待选点之间的欧式距离来计算收敛性
C
r
o
w
d
Crowd
Crowd:在径向空间里同一个网格内被选择的点的个数来计算分布性
关于径向过程的参考:《A radial space division based evolutionary algorithm for many-objective optimization》
一个m维的向量根据径向权重参数矩阵
W
1
W_1
W1和
W
2
W_2
W2可以投影到2维的空间中,根据n和
B
l
B_l
Bl,
B
u
B_u
Bu可以将2维径向空间分成
m
/
n
m/n
m/n个网格,每个网格有一个
c
r
o
w
d
(
G
s
)
crowd(G_s)
crowd(Gs)表示这个网格内解的个数;每个解有一个con(P)表示这个解的收敛性,
c
o
n
(
P
)
=
∣
∣
P
−
m
i
n
P
m
a
x
P
−
m
i
n
P
∣
∣
con(P)=||\frac {P-min\;P}{max \; P-min \;P}||
con(P)=∣∣maxP−minPP−minP∣∣表示这个解离当前种群中最优解的距离(标准化)。
进行K次循环,每次循环先找一个crowd最小的网格,在该网格内计算 F i t ( Q , P R ) Fit(Q,P_R) Fit(Q,PR)值,得到最小的解,将该个体放入待参考的种群中,将该解从原始种群中除去,更新该解所在的网格crowd=crowd+1,这样求得的解应该是在满足分布性的基础上收敛性最好的解。最后得到K个带参考解
参考解的数量会影响分类边界的分类效果,也就是影响到种群的多样性和分布性
| 目标个数 | K的选择 | 描述 |
|---|---|---|
| 3、4 | 强调多样性的维持,K应该要比较大 | – |
| ≥ 4 \geq 4 ≥4 | 强调收敛,K小一些比较合适 | 将更多的非支配解分在类别Ⅰ中,确保类别Ⅱ的收敛 |
根据不同的实验对比得到K=6表现比较稳定
B) 分类模型管理方法(surrogate management method)
1)模型初始化
FNN的结构如下所示,所有的权重w均是随机在[0,1]的数字,初始时是随机生成的权重参数,后面随着模型的训练进行更新
| 结构 | 描述 | 激活函数 |
|---|---|---|
| 输入层 | d维输入(d表示决策变量的个数) | |
| 隐层 | H个隐层神经元 | sigmoid |
| 输出层 | 1维输出 | sigmoid |
s i g m o i d = 1 1 + e − λ x sigmoid=\frac {1} {1+e^{-\lambda x}} sigmoid=1+e−λx1
2)模型更新
将数据分为3:1的比例,是按照已经分好类的Ⅰ和Ⅱ中各选择1/3和3/4的解作为验证和训练数据。
- 模型使用LM(Levenberg-Marquardt back-propagation method)作为反馈函数。
- 每一个测试样例分别迭代50次。
- 使用一个存档来存储用适应度函数计算出来的解
3)模型验证
使用交叉验证计算FNN的不确定性。
- 分别计算类别Ⅰ,类别Ⅱ和测试集的误差,并使用MAE(mean absolute error)计算误差,可以得到类别Ⅰ/Ⅱ的平均绝对误差
p
1
p_1
p1、
p
2
p_2
p2。
M A E = Σ i = 1 ∣ Q c ∣ a b s ( c − C p i ) ∣ Q c ∣ MAE=\frac {\Sigma _{i=1} ^{|Q_c| }abs(c-C_{p_i})} {|Q_c|} MAE=∣Qc∣Σi=1∣Qc∣abs(c−Cpi)
表示类别c的测试误差, ∣ Q c ∣ |Q_c| ∣Qc∣表示所有类别c的的集合的元素个数
4)模型辅助选择原则
根据精英原则,我们需要尽可能多的选择类型Ⅱ的个体保留。
联合测试误差 p 1 p_1 p1、 p 2 p_2 p2来评估FNN的不确定性,判断由模型得出的解是否可信,结合不确定性判断是否需要使用目标函数计算来选择promising solution。
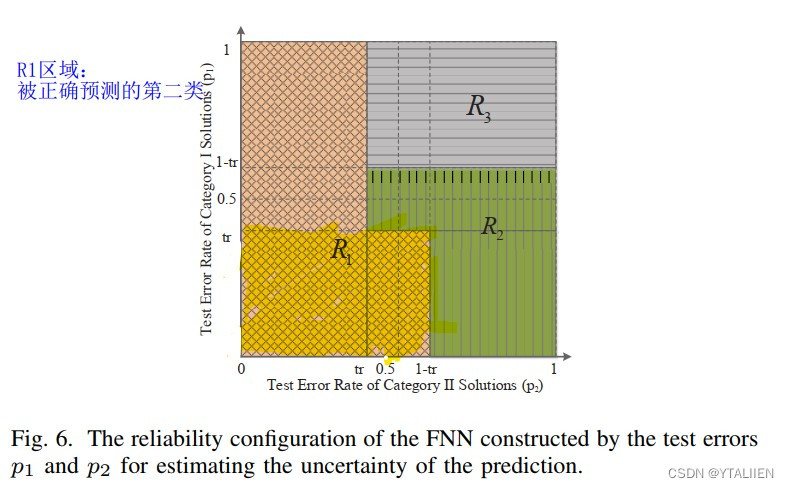
- R1区域中
- p 2 < t r p_2 < tr p2<tr (棕色部分):表明分类器正确预测了第Ⅱ类
- p 1 < t r a n d p 2 < ( 1 − t r ) p_1<tr \quad and \quad p_2 <(1-tr) p1<trandp2<(1−tr) (黄色部分):表明对于Ⅰ的分类是可信的,因此预测到的Ⅰ类是可以丢弃的。需要通过调节阈值来进行分类器的准确度改善。
- R2区域(绿色部分):对于Ⅰ和Ⅱ类都未正确地分类,这些解都不需要使用真实的目标函数来评估。
- R3区域(灰色部分):在这个区域里,p2较大,因此本该属于第Ⅰ类的解很有可能被分为了第Ⅱ类,因此,被分为第Ⅰ类的解应该使用适应度函数计算来估计,它们很有可能被分为第Ⅱ类。
如果一个解分布在R1,这个被分为Ⅱ类的解用于生成子代直到终止条件;
如果一个解分布在R3,这个被分为Ⅰ类的解用于生成子代直到终止条件;
否则,则没有解被选择。
C) 模型准确性分析
使用如下指标来评价FNN的准确性。
{
C
p
1
,
C
p
2
,
.
.
.
,
C
p
∣
Q
∣
}
\{ C_{p_1} ,C_{p_2} ,...,C_{p_{|Q|}} \}
{Cp1,Cp2,...,Cp∣Q∣}:表示使用FNN预测的解
{
C
r
1
,
C
r
2
,
.
.
.
,
C
r
∣
Q
∣
}
\{ C_{r_1} ,C_{r_2} ,...,C_{r_{|Q|}} \}
{Cr1,Cr2,...,Cr∣Q∣}:表示使用目标函数计算而得到的真实的分类
表示所有预测中被预测为第Ⅱ类的比例 r p = Σ i = 1 ∣ Q ∣ ( C p i i s c a t e g o r y Ⅱ ) ∣ Q ∣ 表示所有预测中被预测为第Ⅱ类的比例\quad rp=\frac {\Sigma ^{|Q|}_{i=1} (C_{p_i} \; is \; category\; Ⅱ)}{|Q|} 表示所有预测中被预测为第Ⅱ类的比例rp=∣Q∣Σi=1∣Q∣(CpiiscategoryⅡ)
表示真实的样本中所有第Ⅱ类的比例
r
r
=
Σ
i
=
1
∣
Q
∣
(
C
r
i
i
s
c
a
t
e
g
o
r
y
Ⅱ
)
∣
Q
∣
表示真实的样本中所有第Ⅱ类的比例\quad rr=\frac {\Sigma ^{|Q|}_{i=1} (C_{r_i} \; is \; category\; Ⅱ)}{|Q|}
表示真实的样本中所有第Ⅱ类的比例rr=∣Q∣Σi=1∣Q∣(CriiscategoryⅡ)
r
p
−
>
r
r
rp->rr
rp−>rr,
∣
r
p
−
r
r
∣
|rp-rr|
∣rp−rr∣越小,表明FNN的准确性越高

D)环境选择
继续使用径向过程进行环境选择,参数K变为N(种群大小)
详情见上述